FAIR Data Digest #23
Open data of 16.2 million Dutch vehicles that can be used to enrich Wikidata

Hi everyone,
today’s edition is about FAIR data that is not necessarily related to cultural heritage, but related to cars 🚗. We will have a look into an Open Data dataset of the Dutch government that provides data which hopefully helps me to answer some questions about child safety seats. Statistics shown in this post come from this GitHub repository.
As someone who sometimes has to use car-sharing, I want to know if a car is equipped with a child safety seat or at least has the ISOFIX (Q1320419) attachment points to easily mount one. Whereas car fleets of commercial car-sharing services usually consist of a limited number of similar car models, the fleets of more community-driven initiatives like Dégage (Q107390097) in Flanders, Belgium consist of a wide range of individuals’ cars, and hence a large variety of car models.
As a user I can usually search and filter cars of the fleet. Oftentimes some structured information such as “has child seat” is available. Although it’s possible that not all attributes are available as search filter in the application of the company or initiative. Also, some information might be provided as free text by the owner and this usually is not searchable. Here FAIR data can make a difference. On the one hand provide a better search experience for the end user and on the other hand a be a useful and rich data source for the provider to enrich and link their data!
There is already a lot of data about different car models on Wikidata. However, not every model is described in large detail. Some attributes might be missing. How could we possibly enrich those automatically?

Long story short: apparently in the Netherlands a license plate is related to the car and not the owner. Additionally, the Dutch government provides Open Data. Hence there are open datasets of all 16.2 million cars in the Netherlands, including technical data about the car as well as administrative data (of course without private information). Given the fact that the Netherlands is a wealthy country with many car owners, we probably will find data of almost all sorts of cars in the Netherlands that can be used to enrich Wikidata! This not only makes the data more FAIR and interlinked with the rest of Wikidata, but also makes it possible that the international community can enrich missing information.
Short-story long: have a look at the post below where I describe how to download and analyze the dataset to subsequently enrich Wikidata with it. The data analysis is available as a Jupyter notebook on GitHub.
As a note upfront: technically it is possible to create Wikidata entities for all cars in the Netherlands, useful for all kinds of environmental or economic analysis. However, in this post I focus on the more limited number of car models within the data. Also not every field is always filled in, which makes the data incomplete too.
Getting the Dutch open data about license plates
Data from the Dutch government about mobility is available here. More specifically, this file contains 16.2 million rows with 96 different attributes for each registered car. There are also possibilities to analyze and inspect the data by using the web interface of their website. Different Application Programming Interfaces (APIs) are provided as well!
I preferred to download the data to do some analyses myself. First of all, downloading 16.2 million rows of data takes a few hours! For me it was even interrupted after 14.6 million rows. Hence my analysis is based on partial data. By the way, the data is also available as RDF, but for some reason I only got 22MB of RDF with a successful download. It definitely was not just metadata about the dataset, but data about actual cars. Anyway, CSV is fine too!

More nerdy details about the download process: After clicking to download the file nothing seemed to happen, the Download icon in Firefox didn’t move. However, I got a warning from my Ubuntu system that I am running out of disk space, so definitely something was downloaded. With the command watch df -h I could confirm that my hard drive was constantly filled. I saw that a new temporary file was added by Firefox in /tmp. I started to make space and could estimate by the current size and the current number of rows (command: wc -l) that I would need additional 10 GB. Even though the download failed according to the Firefox UI, I could simply use the partial .part file. Luckily it was a plain CSV file that is not broken if rows are missing.
What’s inside the dataset?
The main dataset consists of 96 columns. Unfortunately not all columns always contain values. It remains to be seen which data this dataset provides that are not already on Wikidata. The script I wrote simply iterates over given columns in a streaming manner to count statistics. Iterating over all rows takes around 3 minutes and the progress is shown thanks to the Python library TQDM.
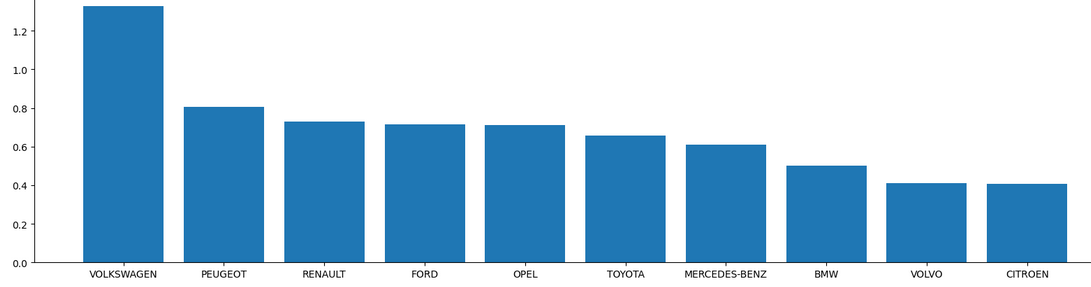
According to the 90% of the data that I could fetch, the Dutch ride more than 10k different brands of cars. Mainly Volkswagen (more than 1.3 million registered Volkswagens). Followed by Peugeot, Renault and Ford (each between 700k and 800k).
You will find more statistics in the Jupyter notebook of this GitHub repository and by installing it (and downloading the data) you can create more statistics.
What’s next and remarks
This journey began with the question which car is equipped with ISOFIX attachment points. Did I find this answer? No, unfortunately not. There are commercial players that provide this data for a price, e.g. via the website of a Dutch car magazine. Even though information about equipment such as ISOFIX is their added value, the underlying data about the cars is Open Data.
A next step could be to group the data based on brand and model and reconcile it with Wikidata. Then we would be able to see which of the linked Wikidata items miss attributes that are provided by our data. By adding found data to Wikidata in a structured manner, this data can become interlinked with the rest of Wikidata and would be available to a broader audience. An audience that does not necessarily need to know Dutch and the specific open data websites of the Dutch government.
That’s it for this week of the FAIR Data Digest. If you found the content interesting, please share and subscribe. See you next year after the holidays!
Sven
PS: thanks to the Rogue Scholar, this post can be cited by using a Digital Object Identifier (DOI) which you can find on the linked Wikidata page Q123755598 after the post was published.