FAIR Data Digest #19
on a fast Python clustering algorithm for bibliographic data and a talk about Belgian journalism at the DH virtual discussion group

Hi everyone,
welcome back to today’s edition in which I share a work update related to bibliographic data and provide information to an upcoming interesting talk.
🏢 Books exist in many different versions. The same book might be published as paperback or as ebook and that even in different translations. Both for user experience and data quality it is interesting to cluster the bibliographic records of such editions of a book together. Algorithms to do that were described in several research papers in the past. But I couldn’t find any easy to use open source tool. In today’s work update I talk about the clustering and present a fast implementation in Python that I developed recently that hopefully can easily be reused. #FAIRsoftware.
📅 Are you interested in Digital Humanities or are you curious about Belgian journalism? Join us next Monday for the next online session of The DH virtual discussion group for early career researchers where Sergio Alonso Mislata will present behind the scenes of his work for the Centre for Archives on the Media and Information (CAMille), a joint lab between the Royal Library of Belgium and the Université Libre de Bruxelles (ULB).
🏢 Work update: FRBR clustering
What do the books "The invention of Nature" and "De uitvinder van de natuur" have in common? Well, they are all different versions of the same work "The invention of nature" by Andrea Wulf (Q24908385), whether it is in a different format or a different language. In technical terms, these records are on the so-called manifestation level. But for simplicity I will refer to them simply as book versions.
Library catalogs usually contain records of all the different versions. However, identifying the higher work level has advantages for both the librarians and the users of the catalog. In today’s work update (no pun intended) I want to talk about how I recently did this for the BELTRANS project in a performant way using a so-called inverted index.
A few research papers were published in the past decade about how one can cluster manifestation-level book descriptions in library catalogs to work-level records. I collected a few relevant references in a list at the Open Research Knowledge Graph (ORKG) (Q108127463).
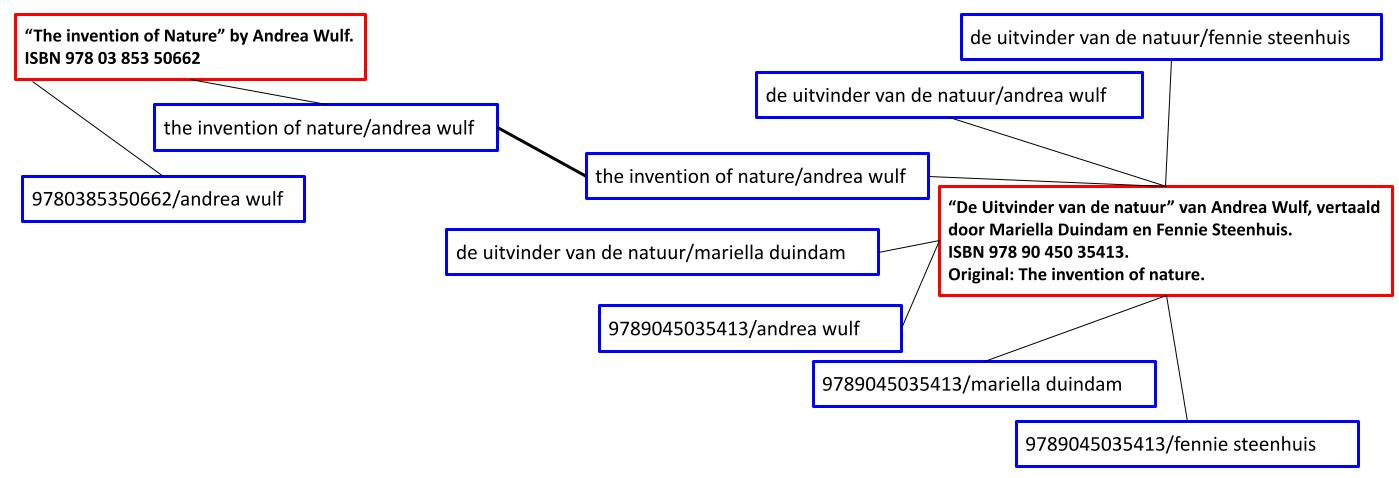
What I missed so far is a practical modern implementation. Something that does not require to install a whole XML-based software stack and a Java application. I implemented such a clustering algorithm in Python and released it in a GitHub repository from the Royal Library of Belgium (DOI: 10.5281/zenodo.10011416). Check out my blog where I provide some more details and behind-the-scenes.
That’s it for this week of the FAIR Data Digest. If you found the content interesting, please share and subscribe. See you in two weeks!
Sven